はじめに
2025年3月1日より、個人事業主として開業申請いたしました。 当面は続けられる限りフリーランス的な働き方を併用しながら、今まで自分が挑戦できなかった分野の開発に取り組んでいこうと考えております。
で、サラリーマン的に趣味的に作っていた LUT-Network が長らく放置状態だったので、少しサルベージしたいなと考え始めています。
X(Twitter)に過去にアイデアだけはいろいろ投稿していますが、少しまとめておこうと思います。
普通のDNNとのハイブリッド
LUT-Network はパラメータを即値として織り込んだ状態で、ネットワーク構造とセットで合成してしまうものです。
その構成上、パラメータを入れ替えながら演算器を再利用することはしていません。これはリアルタイム信号処理には適しているのですが、課題になるケースもあります。
1つは CNN などのプーリング層など stride が 2以上のフィルタで画像サイズが縮小されたときに演算器の利用効率が下がってしまうというものがあります。
多くのCNN構造ではプーリング層前後で、縦横のサイズが1/2 の合計1/4になる(チャネル数が2倍になることが多い)という構成をとります。この時、LUT-Network のようにカメラ信号を直接入力するタイプのネットワークだと、4サイクルに1回しかデータが到着しなくなり、さらに 16サイクルに1回、64サイクルに1回と、プーリング層の後段のLUTほど遊休状態が増えていきます。これは LUT テーブルにパラメータを置いてしまっている関係上、LUTが再利用できないために起こります。
この回避方法として過去に挙げたアイデアとしては
- CFGLUT5 や SRLC32E を使い LUTテーブルを書き換える
- 素直に従来からあるパラメータ分離の再利用型のパーセプトロンとハイブリッドにしてパラメータを分散RAMやBlock-RAMなどに置く
というものがあります。これは普通のDNNとの組み合わせに他ならないのであまり新規性もなく手を付けていなかったのですが、検討しておく事項なきはします。
例えば 3x3x32 チャンネルの畳み込み層の処理は、16サイクルに一回しかデータが来ないなら DSP などの積和構成を 18並列で準備して、それぞれ16個のパラメータを持ったメモリを用意すれば捌けることになります。 メモリも小さいうちは分散RAM、多くくなったら Block-RAM を使えばきれいに収まるはずです。
以前、X で 1 + 1/2 + 1/4 + 1/8 + 1/16・・・ = 2 という話をつぶやきましたが、まさにそういう話で、後段に行くほど規模が小さくなっていくので、リアルタイムであってもよりリッチな構成を組み込める可能性が出てきます。
(寝ぼけていました、pointwise 等のチャネル方向計算は入力チャネル数×出力チャネル数なので演算量減りませんね。入力数が6とかに制約されるLUT-Netに毒されておりました)
過去にも言葉でしか書いてなかった気がするので、なんとなく絵にすると下記のような感じでしょうか。

例えばカメラから毎サイクルピクセルデータが出てきていたものを LUT-Network で処理したものを MaxPooling 層に入れると、歯抜けになり、FIFOを入れると4サイクルに1回データ処理すればよくなります。
LUT-Network の Convolution 層の中身と同様にブロック化して 3x3 などにした後は、4サイクルかけて積算すればいいわけです。
マルチサイクルの積和部分を少し詳しく書くとこんな感じでしょうか。

バイアス項はアキミュレータのリセット値としておけばメモリの重みを複数サイクルかけて次々足しこんでいくだけで計算できます。もっとも乗算といってもLUT-Network はバイナリなので 1bit の掛け算はとてもシンプルなわけです。
また、LUT-Network の入力についても、バイナリ化が難しいものは一度ここも普通の 多値のパーセプトロン層を通してからバイナリ化する手があります。幸い入力データは RGB の 3値程度のケースが多いので、逆にここだけリッチな構成にする手はありそうな気がします。
いずれにせよ、当方はリアルタイム処理が信条ですので、単に配置した演算器を100%稼働させるというだけではなく、入り口から出口までバランスよく演算器を配置してインターロックすることなくデータを最短レイテンシで通す というところには拘りたいと思います。その場合 bit 精度や並列度をレイヤー別に最適な値で構成していくことが重要になります。
まともに考えると、多値の通常パーセプトロンをすべて回路に収めて、カメラ入力を出力までオンザフライで処理するなどという事を考えた場合、LUT-Network のようなやや強引な圧縮手法を使わないと1つのFPGAに収まめることは難しいわけですが、部分的にであればフルスペックに近い従来 CNN とのハイブリッドはあり得るのかと思っています。
Reservoir Computing での利用
これは fpgax #14 で知った方法ですが、こちらなどにもpdf があるようでとても勉強になります。
私も以前 RNN 的なことがやりたくて、こちらのようなことを考えたことはありますが、やはりRNN の学習はなかなか規模が大きくなり難しさを感じていました。
一方で Reservoir Computing では、RNN とは異なる方法で時系列の情報にアプローチできます。
また Reservoir 部分も LUT-Network の構造を利用できそうに思いますので、これは非常に興味深い取り組みです。
例えば下記のような感じでしょうか?
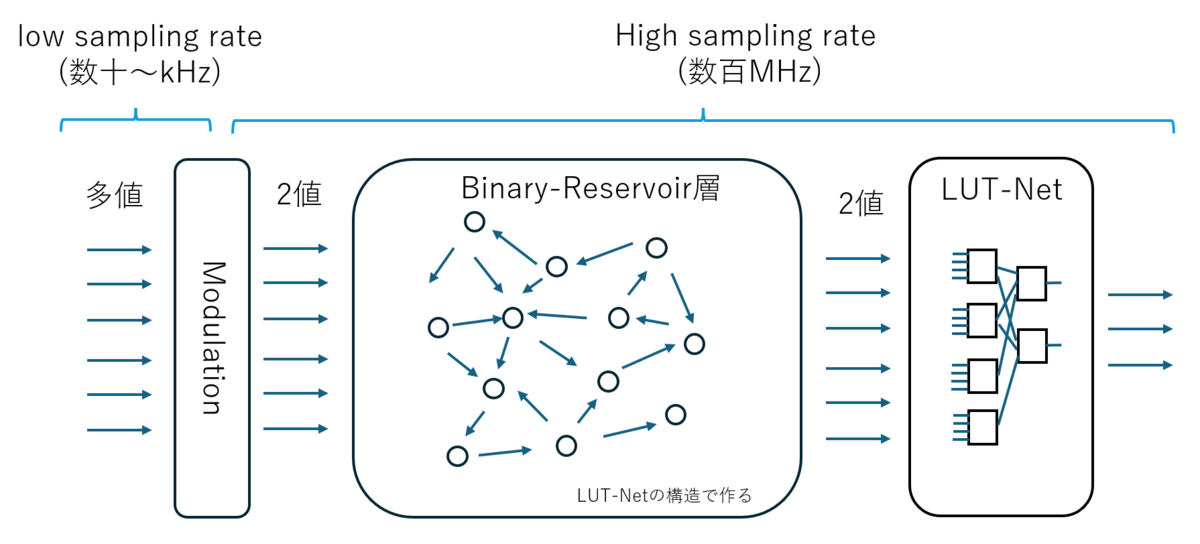
LUT-Network の構造は非常にシンプルがゆえに高周波数で動かすことができますので、Reservoir 部分も含めて LUT-Net の構造で作成すれば非常に高いサンプリングレートで動作できると考えられます。
一方で、入力となるセンサーなどは、そこまで高周波数ではないものもありますので、LUT-Network が今までそうしてきたように バイナリに Modulation して入力すればいいような気がしています。この Modulation というかバイナリエンコードというか、その部分もいろいろ工夫の余地がありそうに思います。
おわりに
まだまだ構想だけで、しばらくはバタバタしそうではありますが、折角の機会ですので、いろいろ取り組んでみたいと思います。

