はじめに
先日 X で下記の動画が流れてきて初めて知りました。
(リアルタイムコンピューティング研究所 を名乗っておきながら、この手の素晴らしい技術をまったくウォッチできておらずニュースで知るというのもお恥ずかしい話なのですが)
VIDEO
少し時間が出来たので今朝になって、こちら のプレスリリースを読み始めたところですが、大変興味深いので、私の好きなセンサー周りを中心に少し素人考察してみようと思います。例によって素人の感想ですので、間違いや嘘が混ざることもあるかもしれませんが容赦ください。
フィジカルAIというバズワードが流行り始めてしばらくたちますが、この分野で日本の技術が復活できる可能性を示してくれた、大変心強い成果であるように思います。関係者の方々に惜しみない賞賛を送りたいと思います。
プレスリリースでは、研究者や技術者の名前までは出ていませんが、こちら の Author を見て見ると実に 49名の連名者がおられ、国際色豊かな一大チームのようですね。
蛇足ですが、名前の入ってない方も大勢おられると思いますし、このクラスの研究者/技術者の年収を考えると人件費だけで毎年軽く10億円単位になっていると思われますので、大きなプロジェクトかと思います。私の研究所(自称)の数万倍ぐらいの予算規模ですね(笑)。
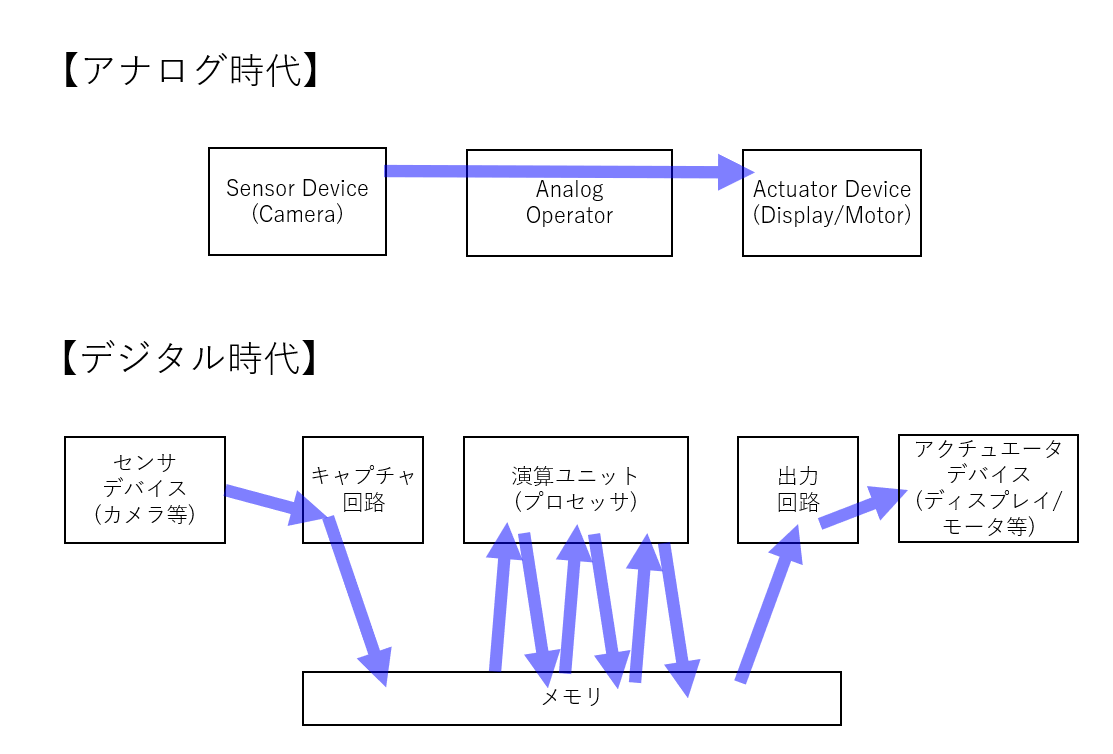
システム構成を見てみよう
先のURLに図が貼られていましたので引用させてもらいます。
Ace構成図
イベントベースビジョンセンサー IMX636(EVS) ×3台
こちら のイベントベースビジョンセンサーで 1/2.5型 で 約92万画素 のセンサーのようです。1280 x 720 で レイテンシは 100 µs以下との事です。マシンビジョンといいつつ 1280 x 720 という AV機器で使われるサイズなあたりが Sony らしいなと思いつつも大変興味深いセンサーです。
これに ガルバノミラーのユニットを組み合わせて GCS(Gaze Control System) と呼んでいるようです。
ガルバノミラー+高速度カメラで卓球の玉を追いかけるのは、東京大学、石川グループのこちら が古くから有名ですが、今回は 1000fps カメラではなく EVS を使っていることが特徴かと思います。
卓球の球は、およそ 30m/s 程度のようですので、1ミリ秒(秒1000コマ)で、3cm 移動する計算です。 一方で、ある程度の変化こそしますが、ラケットで打ったりしたとき以外は、1ミリ秒などの短時間の中ではほぼ等速直線運動をしますので、従来のフレームベースカメラでも1000fps程度あればPID制御などでセンサー中央に卓球の球を捉え続けることが可能なようです。
ではなぜ、今回フレームベースの高速度カメラではなく、もっと速い時間分解能を誇る EVS カメラを使っているのかというと、回転を測るため のようで、実に 500 rad/s (秒80回転)までの回転が測れるそうです。 従来のフレームベースカメラでいうと 10万fps などのオーダーになってしまう時間分解能です。
ちなみに回転が撮りやすいようにボールの方にもマーキングか何かあるっぽいですね。また露光量を稼ぐためと思われますが、赤外照明なども積極的に活用しているっぽいです。
一方で、一般に EVS は動くロボット側に搭載したり、今回のようなガルバノミラーとの組み合わせなどは、本来であれば非常に苦手です。変化したピクセルだけを測ろうとするので、背景が大きく変化すると背景の情報ばかりが出てきてデータ帯域を圧迫してしまい、本来の情報が取り出せなくなるためです。 (鳩の首振りのように細かくミラーを止めたりしているのかとか想像もしてみたのですが)どうも今回は画像処理によって背景成分の除去を行っているようですが、ある程度背景が均一な環境 というのが前提にある可能性が高い気はしています。 少し意地悪な話ですが、背景に観客が大勢いるスタンドが写ってるなどだと、ガルバノミラーが動くたびに大量の背景イベントが発生して困るとかあるんじゃないかと想像してみました。
グローバルシャッターカメラ IMX273 200fps × 9台
こちら やこちら などに情報があるデジカメでも使われているグローバルシャッターのセンサーのようです。 1456x1088@10bit モードで 226 fps で、カラーとモノクロがありますが、三角測量に用いているとのことですので、常識的にはモノクロの方なのではないかと想像します。
撮影ラインを絞ってフレームレートを上げることも出来る筈ですが今回逆に少し下げて 200fps での運用のようです。想像ですが、システム周波数が 1kHz のようですが、その倍数まで落として同期システムにしているのだと想像します。
一般論ですが、多視点カメラを用いて3角測量する場合に最も重要なことは
グローバルシャッターで且つ複数カメラのシャッターをきっちり合わせる事
カメラ位置/レンズ歪などきっちり事前キャリブレーションしておくこと
計測領域の被写界深度を確保するために、F値を下げても写る照明条件を確保すること
方向の異なる映像からきっちり取りたい点で交差する中心を測る画像処理を開発する事
などです。
再帰性反射材など使えると楽なのですが、あくまで競技のできる球を使っているようですので、ここは赤外照明とかでいろいろ頑張っているのではないかと思います。
露光は短くできるとしても 200fps (5ミリ秒) ですと卓球の球は計測中に 15cm ほど進んでしまう計算なのである程度の予測は必要です。ただこのレベルの予測でもボールにラケットを当てるだけの制御ならルールベースである程度行ける可能性はあるのではないかと思います。そこに先の回転の情報なども使って高度に勝つための打ち返し戦略を立てるAIを組み合わせることで、完成度の高いシステムになっているのだと予想します。
ちなみに、もしかすると、このグローバルシャッターカメラで測った位置情報は、先のガルバノミラーの制御にも使われているのかもしれませんね。
計算機構成
有償の論文は読めていないのですが、AI 経由で聞きだすと、どうやらNVIDIAのGPUと専用のハードウェアで計算を行っているようです。
無料の情報の範囲でも 1kHz (1ミリ秒周期)のシステムと、31.25 Hz(32ミリ秒周期)のシステムのハイブリッドと読み取れますので、FPGAなどの専用ハードウェア と GPU でそれぞれハイブリッドな、サブサンプションシステムを作っている可能性はあるのではないかと思います。
卓球はもともと人間同士が競技するものなので、一応人間技の範疇ではあり、身も蓋もない話をすると応答速度数十ミリ秒のGPUで予測だけでもできる可能性はあるのかもしれませんが、人間の持つ分解能の高い連続的な応答や、反射神経部分を補うために 1kHz システムがうまく活用されているのだと思います。
当サイト がいつも妄想しているこれですね。
サブサンプション
リアルタイム処理のサブサンプションはちゃんと考えてシステム設計せずに後付けでハイブリッドにしようとすると、以前こちら で書いたような罠に嵌りますので、初期コンセプトがとても大事だと思います。
深層強化学習(RL)によって訓練された制御ポリシーを使用しているようですが、この辺りも興味深いですね。
1ミリ秒クラスの応答は専用ハードウェアを用意しないとGPUでは難しい領域に入ってくるのですが、私の LUT-Net のように1ミリ秒でやれるAIももちろん、ちゃんと専用計算機を用意すればこのクラスの小規模AIももちろん可能なはずです。そしてなによりGPUでちゃんとAIをやるのと組み合わせることが大事ですね。
アクチュエーション
こちらはもう全然私の知識では及ばなくなってくるのですが、卓球という競技に対応するための高度な機構設計がなされているようです。
一方で、これらを制御する電気的な仕組みについての課題は述べておく必要があるかと思っています。
汎用ロボットの類はしばしインターフェースが遅いケースがあります。私の知る限り、機構自体の応答性は極めて高くモーターに流れる電流が変化すると同時に電流量に応じた加速度がモーターに加えられます。高校物理の話です。
しかしながら、電流を変化させるまでの手順がしばし問題でして、USBなどは論外としつつも、Ether などでも TCP/IP などをまじめにやるとプロトコルスタックで消費する遅延量は大きいです。折角早く計算してもアクチュエーターに高速に指示が出せなければ意味がありません。
一番良いのは専用のものを作ってマイコンやFPGAから直接的にDACを制御することですが、高度なエンコーダーと制御ループの組まれた既存サーボシステムを置き換えるのも一般に容易ではありません。
で、今回のシステムを見ると EtherCAT の文字が書かれています。EtherCAT は物理層としては Ether 規格に準じながらも、TCP/IP のような複雑なことはせずに、機器をデイジーチェーンして超低遅延で制御する規格です。想像ですがこのような低遅延なI/Fに直接乗り入れできる計算機側の専用ハードウェアと、ロボットメーカーやサーボメーカーが誇る高度な制御システムを低遅延で接続することがある程度うまくいっているのではないかと思います。
EtherCAT 自体は個人では簡単には規格書が手に入らないので、私はオレオレプロトコル で以前に少し遊んだ程度なのですが、物理層としては Ether は非常に優秀で、PC用の機材が使えて安価なのでとても素敵ですね。
おわりに
久々にワクワクするニュースが飛び込んできたので、日曜の朝の時間を丸々費やしてしまいましたが、備忘録程度の記事にはなったのではないかと思います。
センシングだけだとなかなかシステムとして可視化できませんが、アクチュエーション入ると楽しいですね。
私も最近FPGAで下記のような1ミリ秒で画像計測の結果をガルバノミラーにフィードバック するおもちゃを作りました。しょぼいですが、年間研究予算は数十万円で一人でやってますのでその点だけは誉めてください(笑)
VIDEO
フィジカルAIという単語が、日本の技術の復権のきっかけになってくれると嬉しいなと思います。
なお、Ace のシステムはあくまで 32ms 後の行動を教師として学習を行っているようです。32ms という応答性は人間には不可能なので、人間からすると超絶技巧なわけですが、裏を返せば卓球という競技は人間でも成り立っているという点で 32ms 後の予測が大いに意味を成す世界なわけです。
ちなみに、私のところでやっている遅延1ミリの超低遅延技術はその10倍早いですので、もし仮に勝てるポイントを追求するとしたら、例えば、テーブルのサイズをどんどん小さくしていき、人間技では競技が成立しない領域に持っていくとか、ランダムに揺れるトラックの荷台で卓球させるとか、予測が効かず、力業の低遅延が生きてくる領域に持ち込んだ際でしょうか。
物理世界は特に人間がかかわるシステムの人間の機械への置き換えは、数十ミリ程度の予測はやりやすいものが多く、遅延で十分で1ミリ秒で予期せぬことに対応する能力が求められることは稀です。
一方で、上のガルバノレーザーのように人間の動きに合わせて遠隔で卓球ロボを制御させるような場合、人間の動きにさらに数十ミリ秒の遅延が乗ると致命的ですので、人間の拡張にAIを使う場合は低遅延は超重要になります。遠隔操作で卓球できるような世界が作れたら面白いとは思います。
私の方は引き続き、そもそも人間には不可能な作業をやらせる や、 人間を拡張する 部分にフォーカスして研究していきたいなと思います。
とはいえこのニュースは衝撃的でしたし、久々に感動させて頂きました。

")



")

")


")

")

")
")






 標準セット(黒)センチュリーアークス")



")
")
