
はじめに
筆者は過去に幾つかこの手のパフォーマンス検証を行い、下記のブログを書きました。
基本的には MPU を自由に弄りやすい、RPU(Cortex-R5) からの検証が主でしたが、今回 ikwzm氏のこちらの記事を読み
アルファ版ながらに uiomem という素晴らしいドライバを公開されておられることを知りました。 APU 側のメモリは Linux に管理されているため、おいそれと手が出せなかったのですが、これなら私にも使えそうです。
同氏の u-dma-buf の方も、キャッシュ制御機能があることは知っていましたが、利用できていなかったので今回いろいろと対応して実験することにしました。
などを整備中です。

実験環境
下記のような構成で AXI バスを 128bit 設定で 333.33MHz で 256kバイト分の Ultra-RAM にアクセスできるようにしました。
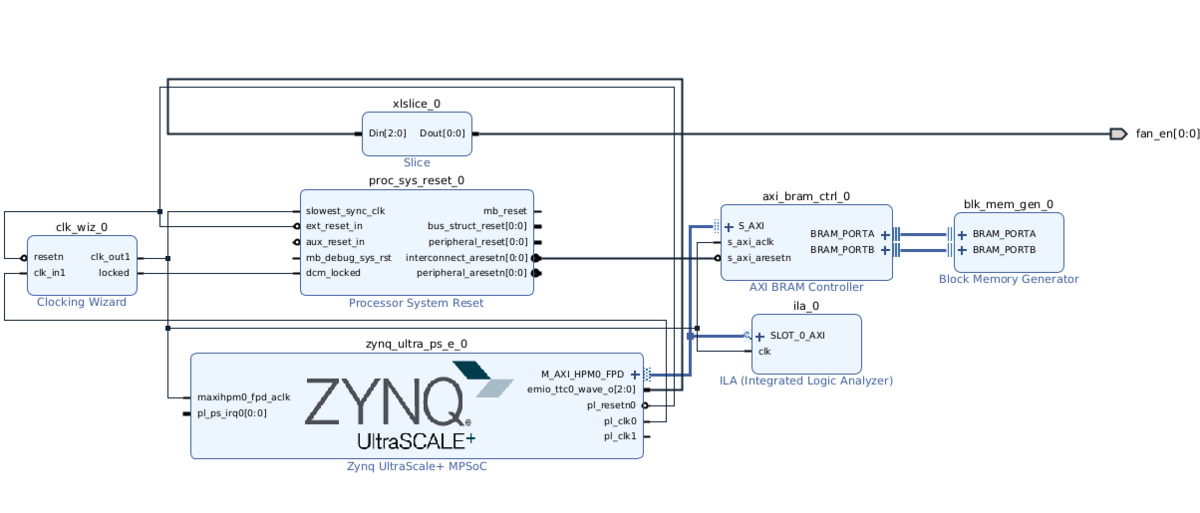
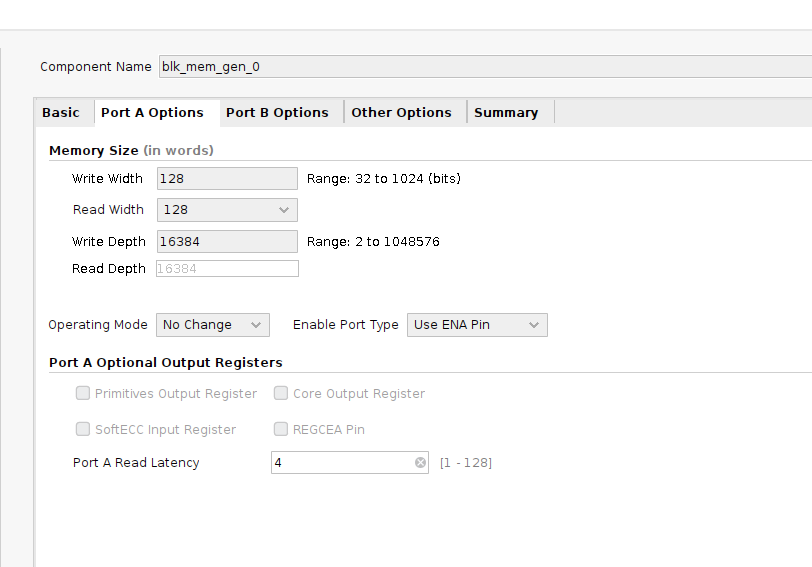
下記のようにレイテンシ 4 まで増やさないとタイミング収束しませんでしたが、サイズがあまり小さいと計測精度が下がってしまうので致し方ないところです。専用回路をうまく組めば read はもう少し攻められるかも知れません。
実験結果
実験結果を下記に張っておきます。
| target | driver | Cache | 方向 | 計測[MB/s] | デバイス限界[MB/s] | 備考 |
|---|---|---|---|---|---|---|
| DDR4 | u-dma-buf | disable | read | 62.78 | 19,200 | 64bit 2400MHz |
| OCM | uiomem | disable | read | 74.98 | 8,000 | 128bit 500MHz? |
| PL | uiomem | disable | read | 72.79 | 5,328 | 128bit 333MHz |
| DDR4 | u-dma-buf | disable | write | 788.50 | 19,200 | 64bit 2400MHz |
| OCM | uiomem | disable | write | 786.96 | 8,000 | 128bit 500MHz? |
| PL | uiomem | disable | write | 696.47 | 5,328 | 128bit 333MHz |
| DDR4 | u-dma-buf | enable | read | 963.49 | 19,200 | 64bit 2400MHz |
| OCM | uiomem | enable | read | 1025.47 | 8,000 | 128bit 500MHz? |
| PL | uiomem | enable | read | 963.35 | 5,328 | 128bit 333MHz |
| DDR4 | u-dma-buf | enable | write | 2034.31 | 19,200 | 64bit 2400MHz |
| OCM | uiomem | enable | write | 2094.54 | 8,000 | 128bit 500MHz? |
| PL | uiomem | enable | write | 2193.73 | 5,328 | 128bit 333MHz |
今のところ
- キャッシュON/OFF は非常に大きく性能に影響する
- DDR4 や OCM はそれ自体の帯域はあるが、シングルコアのみでは上限がありそう
- 逆に PL の 128bit @ 333MHz でもシングルコアの上限にかなり迫っている
というのが見えてきました。早い話がどこにアクセスしても性能はそこまで大きくは変わらなそうです。
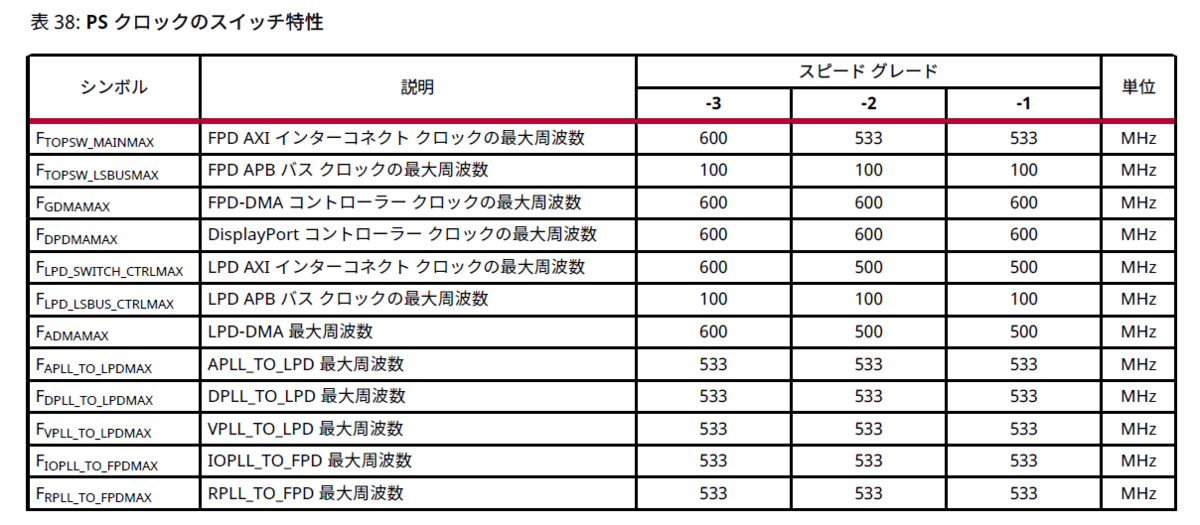
ちなみに OCM のデバイス的な限界おぬりょくですが、バス幅が 128bit であることはTRMに記載がありましたが、周波数がよくわかりませんでした。 下記から類推するに 500MHz でしょうか?
アクセス波形
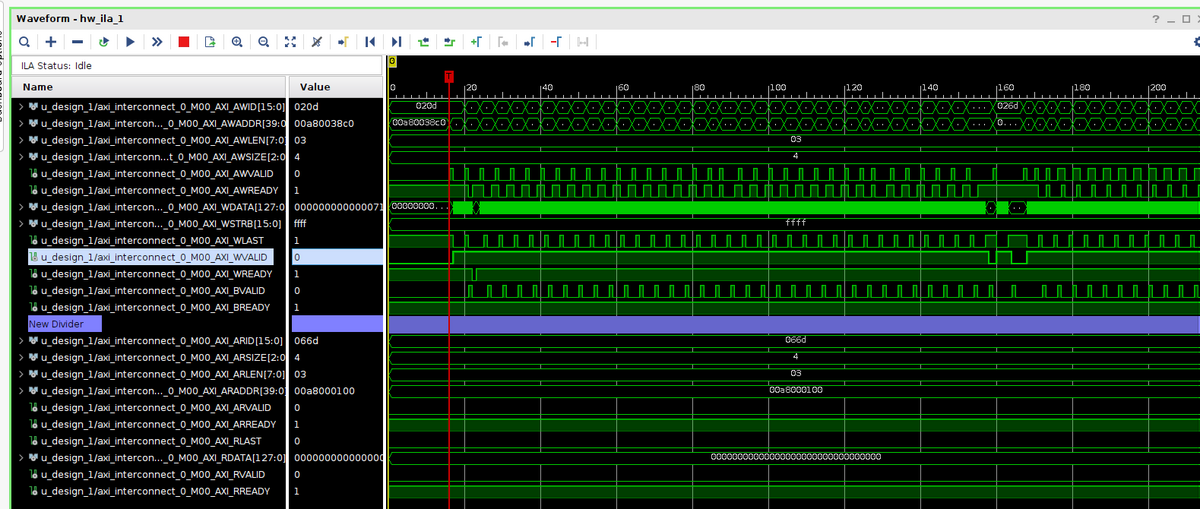
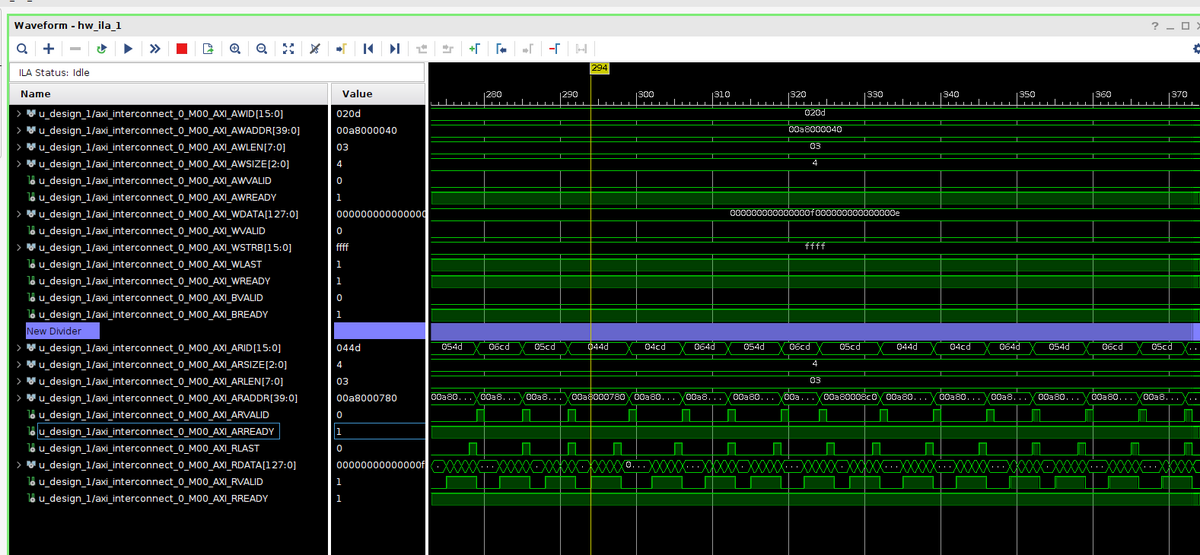
読み書き共に SIZE=4 (128bit) で LEN = 3 (4バースト) の 64バイト単位でのアクセスが確認できており、それなりに帯域は埋まっているようです。

おわりに
PS と PL の通信では、メモリを経由する方法と、直接アクセスする方法があります。
DDR4 などはそれ自身はマルチコアのAPUやGPUなどから共有して使うという事もありそれなりの高帯域ですが、APUの1コアのみからのアクセスですと、そこまで驚く帯域にはならないようです。 一方で、シングルコアからの制御に限れば、PL の 128bit@333MHz という上限はそれほど大きな制約にはならないことが見えてきました。 ですので結局のところ APU においても RPU 同様にキャッシュなどの設定がとても重要になるようです。
筆者は以前から Zynq のメリットは PS と PL が密結合ししていることにあると主張してきました。、 DRAMやOCMを経由する場合も、一度キャッシュを Flush しなければ、PL や DMA に読ませることはできません。メモリを経由すると往復の帯域を消費してしまう上に、レイテンシは2倍かかってしまいます。
Linxu上でのキャッシュ制御という本来面倒な壁があったのですが、uiomem の登場によって、PS-PL 間の直接通信の利便性は今後ますます向上しそうに思います。
まだアルファ版のようですので、是非正式版を楽しみに待ちたいところです。